Tability is a cheatcode for goal-driven teams. Set perfect OKRs with AI, stay focused on the work that matters.
What are Devops Engineer OKRs?
The OKR acronym stands for Objectives and Key Results. It's a goal-setting framework that was introduced at Intel by Andy Grove in the 70s, and it became popular after John Doerr introduced it to Google in the 90s. OKRs helps teams has a shared language to set ambitious goals and track progress towards them.
Crafting effective OKRs can be challenging, particularly for beginners. Emphasizing outcomes rather than projects should be the core of your planning.
We have a collection of OKRs examples for Devops Engineer to give you some inspiration. You can use any of the templates below as a starting point for your OKRs.
If you want to learn more about the framework, you can read our OKR guide online.
The best tools for writing perfect Devops Engineer OKRs
Here are 2 tools that can help you draft your OKRs in no time.
Tability AI: to generate OKRs based on a prompt
Tability AI allows you to describe your goals in a prompt, and generate a fully editable OKR template in seconds.
- 1. Create a Tability account
- 2. Click on the Generate goals using AI
- 3. Describe your goals in a prompt
- 4. Get your fully editable OKR template
- 5. Publish to start tracking progress and get automated OKR dashboards
Watch the video below to see it in action 👇
Tability Feedback: to improve existing OKRs
You can use Tability's AI feedback to improve your OKRs if you already have existing goals.
- 1. Create your Tability account
- 2. Add your existing OKRs (you can import them from a spreadsheet)
- 3. Click on Generate analysis
- 4. Review the suggestions and decide to accept or dismiss them
- 5. Publish to start tracking progress and get automated OKR dashboards
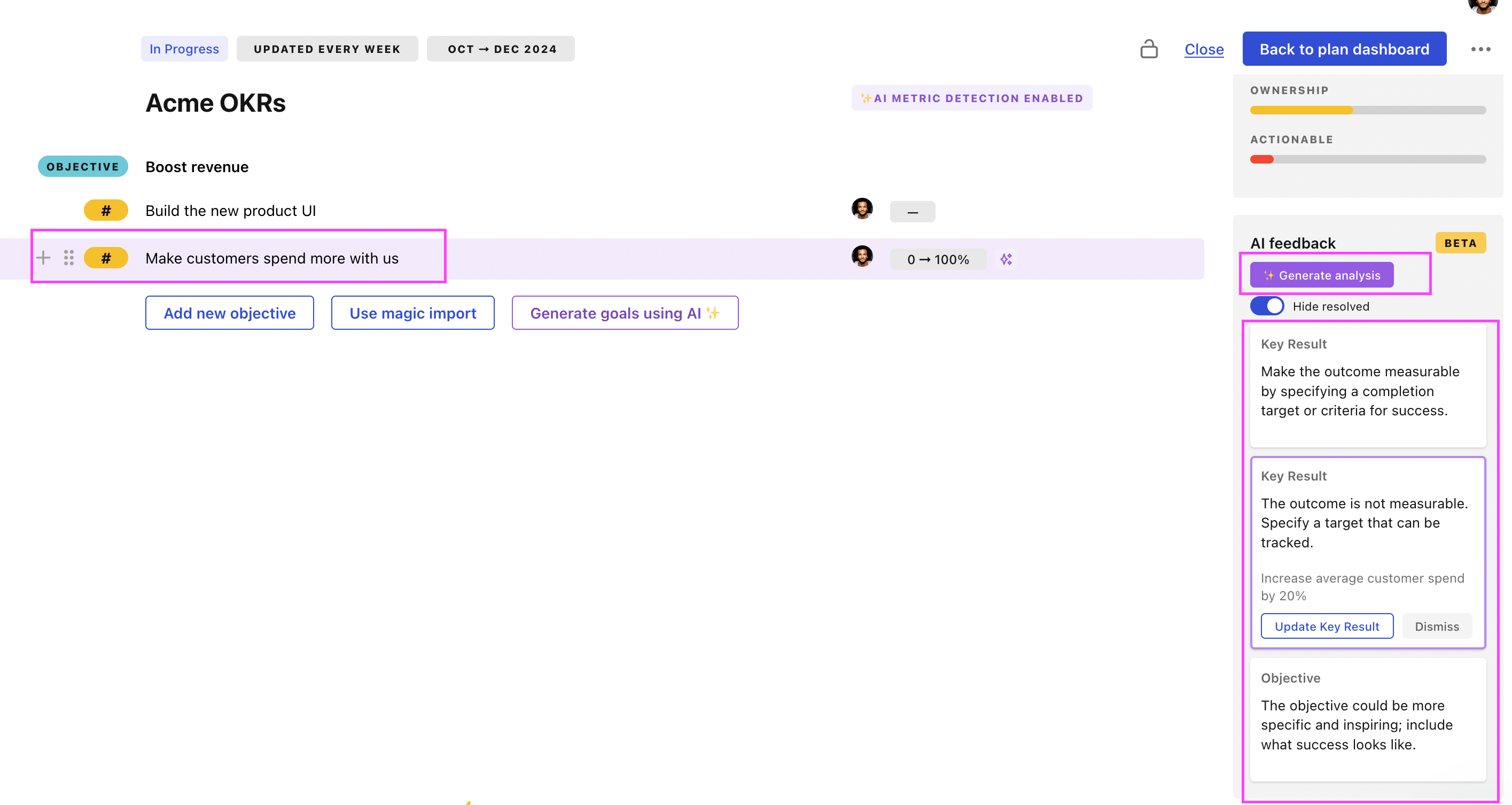
Tability will scan your OKRs and offer different suggestions to improve them. This can range from a small rewrite of a statement to make it clearer to a complete rewrite of the entire OKR.
Devops Engineer OKRs examples
You'll find below a list of Objectives and Key Results templates for Devops Engineer. We also included strategic projects for each template to make it easier to understand the difference between key results and projects.
Hope you'll find this helpful!
OKRs to enhance proficiency in DevOps with AWS
 ObjectiveEnhance proficiency in DevOps with AWS
ObjectiveEnhance proficiency in DevOps with AWS KREarn AWS certified DevOps engineer certification by passing the professional exam
KREarn AWS certified DevOps engineer certification by passing the professional exam Review course material for AWS DevOps engineer certification
Review course material for AWS DevOps engineer certification- Regularly practice with AWS hands-on labs
- Schedule and take the professional exam
- KRTroubleshoot and resolve at least 10 complex problems using AWS DevOps knowledge
- Implement solutions and confirm each problem's resolution
- Develop strategies using DevOps knowledge for troubleshooting each issue
- Identify and categorize ten complex problems within the AWS framework
- KRSuccessfully implement 5 DevOps projects using AWS tools and services
- Schedule project execution timeline and delegate necessary tasks
- Equip team with training on AWS tools and services
- Identify and prioritize 5 suitable projects for a DevOps approach
OKRs to improve organizational DevOps practices with DORA
- ObjectiveImprove organizational DevOps practices with DORA
- KRReduce mean time to recovery (MTTR) for critical incidents to X minutes through improved incident response processes
- KRIncrease deployment frequency by X% through continuous integration and delivery
- Implement automated testing to identify and fix issues early in the development process
- Streamline the build and release process to minimize manual intervention
- Invest in continuous integration and delivery tools for seamless and frequent deployments
- Establish a robust version control system for efficient code management
- KRAchieve X% increase in test automation coverage for application releases
- KRImprove employee satisfaction by X% through promoting a culture of collaboration and learning
OKRs to improve organization's DevOps practices and monitoring systems
- ObjectiveImprove organization's DevOps practices and monitoring systems
- KRImplement real-time monitoring for critical systems
- Set up necessary hardware and infrastructure for real-time monitoring
- Research and select a real-time monitoring software solution
- Create a checklist of critical systems to be monitored in real-time
- Train staff on using the real-time monitoring system and troubleshooting potential issues
- KRAchieve 99% uptime for all production services
- Implement automated monitoring systems to detect and resolve service interruptions promptly
- Create redundancy in server infrastructure to prevent single points of failure
- Establish a robust backup and disaster recovery plan for all production services
- Regularly schedule and perform maintenance tasks to optimize system performance and stability
- KRReduce mean time to resolution (MTTR) for incidents by 20%
- KRIncrease adoption of DevOps practices across all teams
- Implement automated CI/CD pipelines for faster software delivery
- Encourage cross-functional collaboration and knowledge sharing between teams
- Regularly review and optimize existing processes to ensure continuous improvement
- Provide comprehensive DevOps training for all teams
OKRs to implement a flawless DevOps pipeline
- ObjectiveImplement a flawless DevOps pipeline
- KRDeliver 100% of production deployments without rollback or hotfix
- Implement thorough QA testing before each deployment
- Establish a robust and effective pre-deployment review system
- Regularly update and educate team on best deployment practices
- KRIncrease developer satisfaction rate with the pipeline to above 90% by addressing identified bottlenecks
- Monitor and measure developer satisfaction post-implementation
- Conduct surveys to identify the current pipeline bottlenecks
- Implement optimization solutions for identified bottlenecks
- KRReduce pipeline failure rate by 50% through process optimization and automated testing
- Optimize current processes to eliminate bottlenecks
- Identify top causes of pipeline failure and address
- Implement automated testing within the pipeline process
OKRs to successfully migrate all applications to a secure DevOps pipeline
- ObjectiveSuccessfully migrate all applications to a secure DevOps pipeline
- KRAchieve zero security incidents post-migration in the reviewed applications
- Regularly review and update security measures
- Implement solid security mechanisms post-migration
- Conduct thorough security checks and audits before migration
- KRTrain 80% of development team on secure DevOps pipeline management
- Identify team members needing secure DevOps pipeline training
- Organize a training program with a competent instructor
- Schedule and implement training sessions for identified members
- KRImplement secure DevOps pipeline framework for 50% of existing applications
- Develop or acquire the necessary secure DevOps pipeline framework
- Identify applications suitable for secure DevOps pipeline implementation
- Roll out the framework across the identified applications
OKRs to enhance DevOps operations and efficiency
- ObjectiveEnhance DevOps operations and efficiency
- KRReduce code deployment downtime by 30% through improved deployment practices
- Implement continuous integration and deployment systems
- Increase automated testing before deployment
- Simplify deployment procedures
- KRImprove system uptime by 20% by optimizing automation processes
- Monitor changes and adjust strategies accordingly
- Evaluate current system uptime and identify weak points in automation processes
- Develop and implement improvements in automation procedures
- KRAchieve certification in two additional DevOps management tools to broaden technical skills
- Study and pass the certification exams
- Research and choose two DevOps management tools for certification
- Enroll in certification courses for the chosen tools
OKRs to streamline DevOps processes for optimized efficiency and reliability
- ObjectiveStreamline DevOps processes for optimized efficiency and reliability
- KRReduce deployment downtime by 35% through automation and configuration management
- Implement automated deployment processes to reduce manual errors
- Configure management tools for efficient system administration
- Regularly update and optimize automation scripts
- KRImprove incident response time by 20% with enhanced monitoring tools and protocols
- Train team on new tools and swift response strategies
- Implement advanced monitoring tools for quicker incident detection
- Develop robust response protocols for urgent incidents
- KRValidate 100% of codes by implementing a comprehensive continuous integration pipeline
- Implement a robust continuous integration pipeline
- Initiate an automated code validation process
- Periodically audit pipeline to ensure 100% code validation
OKRs to implement a new CI/CD platform for seamless software deployment and delivery
- ObjectiveImplement a new CI/CD platform for seamless software deployment and delivery
- KRConfigure and successfully integrate the chosen CI/CD platform with the existing development toolchain
- Integrate the CI/CD platform with version control systems and build automation tools
- Test the integration to ensure a seamless workflow within the existing development toolchain
- Set up and configure the chosen CI/CD platform to align with the development toolchain
- Research and select an appropriate CI/CD platform for the existing development toolchain
- KRIdentify and evaluate at least three potential CI/CD platforms based on specific criteria
- KRImprove the average deployment time by 30% through automation and optimization efforts
- Optimize server and network configurations to speed up deployment and improve efficiency
- Automate manual tasks during deployment process to reduce time and human errors
- Implement continuous integration system to streamline software deployment process
- Identify and remove bottlenecks in the current deployment workflow
- KRIncrease deployment frequency by 50% compared to the previous quarter, with zero critical production incidents
OKRs to improve system availability to achieve 999% uptime
- ObjectiveIncrease system uptime
- KRImprove system redundancy and failover capabilities
- Use load balancing to distribute traffic across multiple servers
- Create backup systems in different geographic locations
- Regularly test failover and recovery processes
- Implement automated failover mechanisms
- KRImplement proactive system monitoring
- Regularly review system metrics and identify areas for improvement
- Define and create alerts for critical system events
- Develop a process for reviewing and responding to alerts
- Set up monitoring tools for infrastructure
- KRIncrease system performance by 25%
- Upgrade hardware and software components as per audit recommendations
- Conduct a system audit to identify bottlenecks and inefficient processes
- Optimize system settings and configurations to reduce resource consumption
- Implement a system monitoring and alert system to minimize downtime
- KRDecrease unplanned downtime by 50%
- Conduct regular equipment inspections
- Increase spare parts inventory
- Improve operator training on equipment maintenance
- Implement predictive maintenance program
OKRs to improve Kubernetes monitoring efficiency and effectiveness
- ObjectiveImprove Kubernetes monitoring efficiency and effectiveness
- KRReduce the average time to detect and resolve Kubernetes issues by 30%
- Conduct regular performance analysis and optimization of Kubernetes infrastructure
- Establish a dedicated incident response team to address Kubernetes issues promptly
- Consistently upskill the DevOps team to enhance their troubleshooting abilities in Kubernetes
- Implement comprehensive monitoring and logging across all Kubernetes clusters
- KRIncrease the overall availability of Kubernetes clusters to 99.99%
- Regularly conduct capacity planning to ensure resources meet cluster demand
- Continuously update and patch Kubernetes clusters to address vulnerabilities and improve stability
- Establish a robust disaster recovery plan to minimize downtime and ensure quick recovery
- Implement automated cluster monitoring and alerting for timely detection of availability issues
- KRImplement a centralized logging solution for Kubernetes events and errors
- Regularly review and analyze logged events and errors for troubleshooting and improvement purposes
- Configure the Kubernetes cluster to send events and errors to the selected logging platform
- Define appropriate filters and alerts to monitor critical events and error types
- Evaluate and choose a suitable centralized logging platform for Kubernetes
- KRIncrease the number of monitored Kubernetes clusters by 20%
- Develop a streamlined process to quickly onboard new Kubernetes clusters
- Configure monitoring agents on new Kubernetes clusters
- Regularly review and update monitoring system to maintain accurate cluster information
- Identify potential Kubernetes clusters that can be added to monitoring system
Devops Engineer OKR best practices
Generally speaking, your objectives should be ambitious yet achievable, and your key results should be measurable and time-bound (using the SMART framework can be helpful). It is also recommended to list strategic initiatives under your key results, as it'll help you avoid the common mistake of listing projects in your KRs.
Here are a couple of best practices extracted from our OKR implementation guide 👇
Tip #1: Limit the number of key results
The #1 role of OKRs is to help you and your team focus on what really matters. Business-as-usual activities will still be happening, but you do not need to track your entire roadmap in the OKRs.
We recommend having 3-4 objectives, and 3-4 key results per objective. A platform like Tability can run audits on your data to help you identify the plans that have too many goals.
Tip #2: Commit to weekly OKR check-ins
Don't fall into the set-and-forget trap. It is important to adopt a weekly check-in process to get the full value of your OKRs and make your strategy agile – otherwise this is nothing more than a reporting exercise.
Being able to see trends for your key results will also keep yourself honest.
Tip #3: No more than 2 yellow statuses in a row
Yes, this is another tip for goal-tracking instead of goal-setting (but you'll get plenty of OKR examples above). But, once you have your goals defined, it will be your ability to keep the right sense of urgency that will make the difference.
As a rule of thumb, it's best to avoid having more than 2 yellow/at risk statuses in a row.
Make a call on the 3rd update. You should be either back on track, or off track. This sounds harsh but it's the best way to signal risks early enough to fix things.
Save hours with automated Devops Engineer OKR dashboards
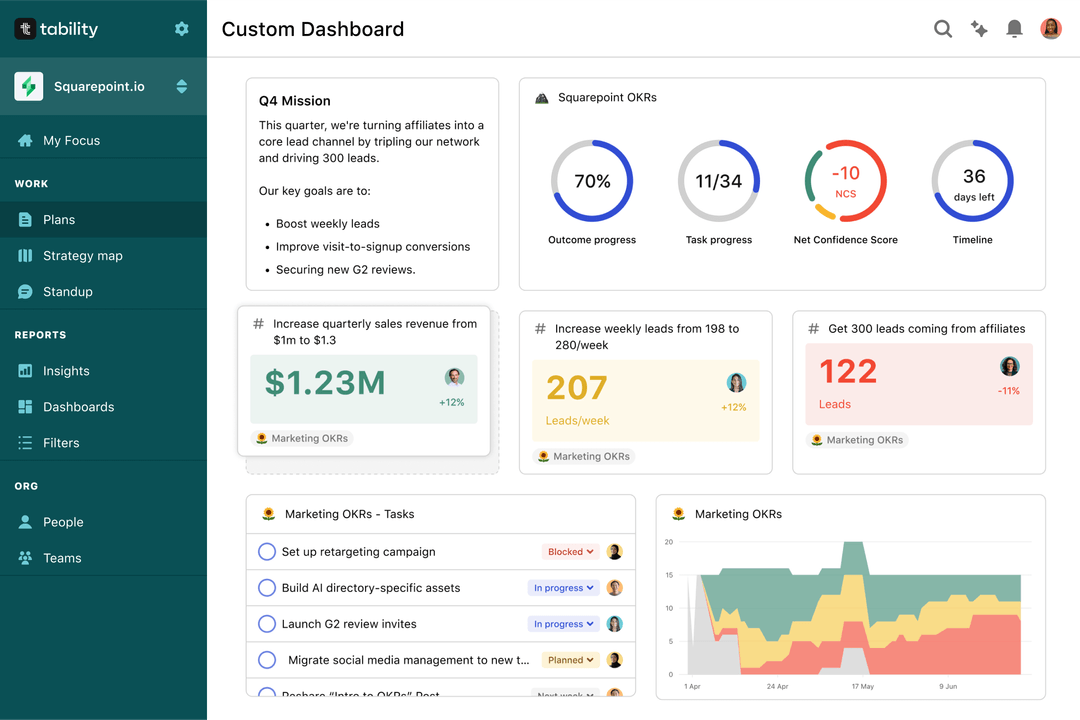
OKRs without regular progress updates are just KPIs. You'll need to update progress on your OKRs every week to get the full benefits from the framework. Reviewing progress periodically has several advantages:
- It brings the goals back to the top of the mind
- It will highlight poorly set OKRs
- It will surface execution risks
- It improves transparency and accountability
Spreadsheets are enough to get started. Then, once you need to scale you can use Tability to save time with automated OKR dashboards, data connectors, and actionable insights.
How to get Tability dashboards:
- 1. Create a Tability account
- 2. Use the importers to add your OKRs (works with any spreadsheet or doc)
- 3. Publish your OKR plan
That's it! Tability will instantly get access to 10+ dashboards to monitor progress, visualise trends, and identify risks early.
More Devops Engineer OKR templates
We have more templates to help you draft your team goals and OKRs.
- OKRs to develop a new in-product referrals program
- OKRs to successfully transition from monolith to microservices architecture
- OKRs to be the employer of choice in our industry
- OKRs to become a computer security expert
- OKRs to become Brazil's top recommended OKR Trainer and Consultant
- OKRs to boost event participation and enhance attendee satisfaction