These Data Engineer OKR templates are meant to help teams move from ideas and projects to measurable business outcomes. Use them as a starting point, then tailor the metrics and initiatives to the reality of your company.
Use Data Engineer OKRs to define what success looks like this quarter, then track them weekly so the team can quickly spot blockers, learn, and adjust execution.
This page shows the top 2 of 2 templates for data engineer, with internal links to related categories and guidance for adapting the examples to your team.
Last template update in this category: 2024-10-07What this category is for
- Teams that need a clearer operating rhythm for data engineer work.
- Managers who want examples they can adapt into outcome-focused quarterly plans.
- Leaders comparing adjacent categories before choosing the best OKR direction.
Best outcomes to track
- Data Engineer priorities tied to measurable business outcomes.
- Weekly check-ins that surface blockers before they become delivery issues.
- Better alignment between initiatives and the metrics that matter.
Related categories
Use these linked categories to explore adjacent planning areas and strengthen the internal topic cluster around data engineer.
Priority hubs
Data Engineer OKR examples and templates
Start with these top 2 examples from 2 total templates in this category, then adapt the metrics and initiatives to fit your team's constraints and operating cadence.
OKRs to enhance the performance of Databricks pipelines
 ObjectiveEnhance the performance of Databricks pipelines
ObjectiveEnhance the performance of Databricks pipelines KRImplement pipeline optimization changes in at least 10 projects
KRImplement pipeline optimization changes in at least 10 projects Start implementing the optimization changes in each project
Start implementing the optimization changes in each project- Identify 10 projects that require pipeline optimization changes
- Develop an actionable strategy for pipeline optimization
- KRReduce the processing time of pipeline workflows by 30%
- Implement automation for repetitive, time-consuming tasks
- Upgrade hardware to enhance processing speed
- Streamline workflow tasks by eliminating redundant steps
- KRIncrease pipeline data load speed by 25%
- Implement data compression techniques to reduce load times
- Simplify data transformation to improve throughput
- Upgrade current servers to enhance data processing capacity
OKRs to build a robust data pipeline utilizing existing tools
- ObjectiveBuild a robust data pipeline utilizing existing tools
- KRSuccessfully test and deploy the data pipeline with zero critical defects by the end of week 10
- Deploy the final pipeline by week 10
- Thoroughly debug and test the data pipeline
- Fix identified issues before end of week 9
- KRIdentify and document 100% of necessary features and tools by the end of week 2
- Review product requirements and existing toolsets
- Conduct brainstorming sessions for necessary features
- Document all identified features and tools
- KRAchieve 75% completion of the data pipeline design and construction by week 6
- Continually review and improve design stages for efficiency
- Allocate resources for swift pipeline design and construction
- Establish milestones and monitor progress each week
How to use Data Engineer OKRs well
Strong OKRs keep the team focused on measurable outcomes instead of a long task list. That means picking a clear objective, limiting the number of competing priorities, and reviewing progress every week.
Use Data Engineer OKRs to define what success looks like this quarter, then track them weekly so the team can quickly spot blockers, learn, and adjust execution.
Choosing software to run these OKRs?
Many teams looking for data engineer OKR examples are also comparing tools to roll them out. If you want to move from examples to execution, review our OKR software comparison guide to compare the best OKR software before you commit to a platform.
Related OKR template categories
If you are building a broader plan, these related categories can help you connect data engineer work to adjacent company priorities.
- project manager OKR templates
- leadership OKR templates
- strategic planning OKR templates
- operations OKR templates
- operations team OKR templates
- sales OKR templates
More OKR templates to explore
- OKRs to enhance knowledge visibility among subject matter experts
- OKRs to streamline workflows and optimize lead generators
- OKRs to increase high-quality leads in the trade finance sector
- OKRs to boost customer inflow to our retail locations
- OKRs to determine the cost of transitioning from SAP ECC to SAP S/4
- OKRs to ensure efficient transition from SAP ECC to SAP S/4
Not seeing what you need?
Use Tability AI to generate OKRs based on a prompt
Tability allows you to describe your goals in a prompt, and generate a fully editable OKR template in seconds.
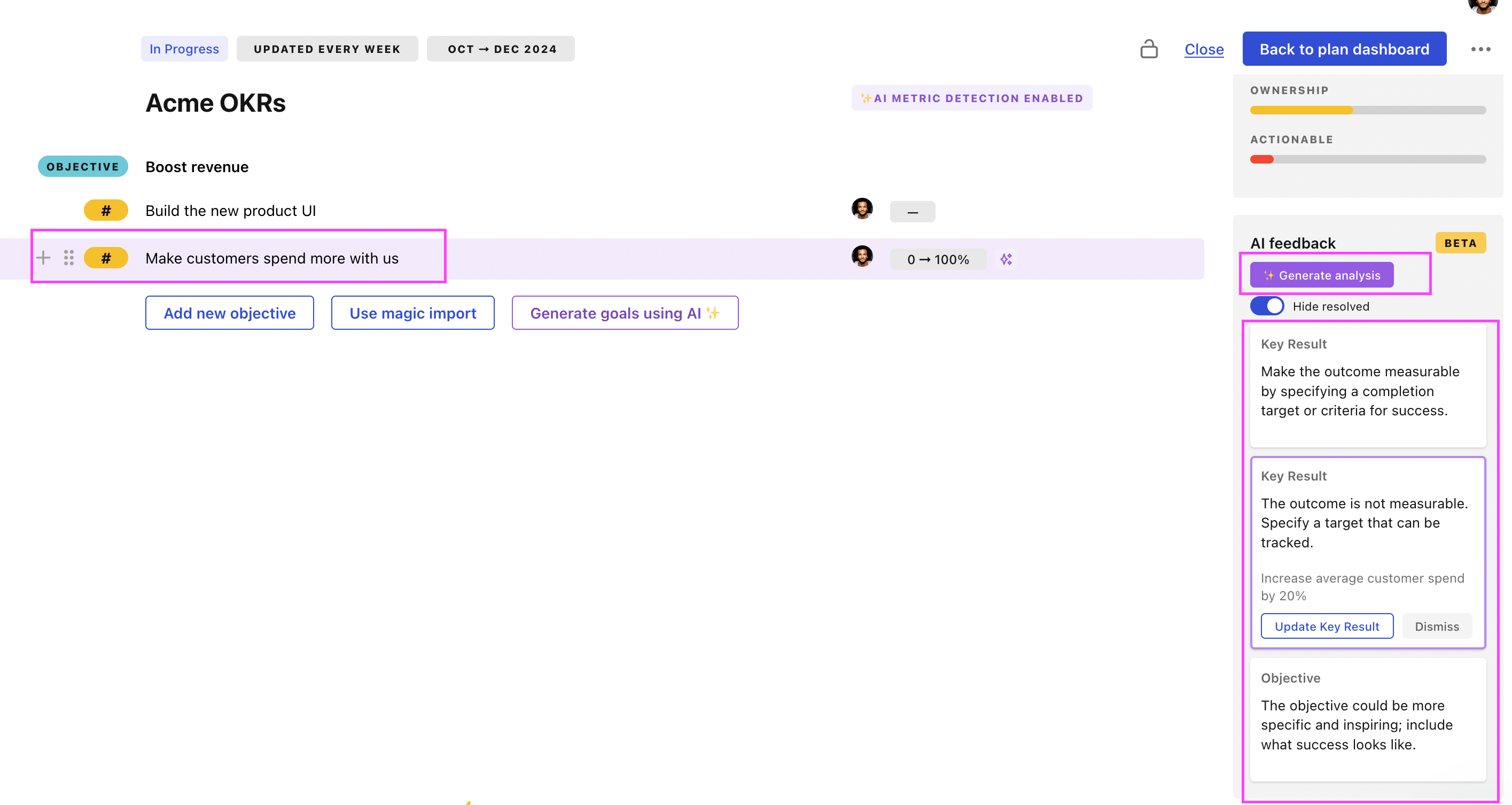
Use Tability feedback to improve existing OKRs
You can also use Tability's AI feedback to improve your OKRs if you already have existing goals. Just import them to the platform and click on the Generate analysis button.
Tability will scan your OKRs and offer different suggestions to improve them. This can range from a small rewrite of a statement to make it clearer to a complete rewrite of the entire OKR.