OKR template to enhance data engineering capabilities to drive software innovation
This sales OKR template is a strong starting point for teams that need better alignment, clearer priorities, and more disciplined goal tracking.
Use it to turn a business priority into a measurable objective, then review progress weekly so your team can adjust execution before the quarter gets away from you.
Your OKR template
The second aspect of this OKR focuses on improving software scalability. To manage large datasets more efficiently, data storage and retrieval mechanisms are optimized. It involves initiatives such as query optimization, adoption of scalable storage systems, and efficient database indexing systems.
The third component aims at increasing data processing efficiency. It looks to optimize data ingestion pipelines and reduce processing time, a necessity in the rapidly evolving digital landscape. Initiatives under this include lagging pipeline optimization, solutions for fast data processing, and an analysis of the efficiency of current data ingestion pipelines.
Lastly, the OKR proposes initiatives on how to achieve each sub-objective. For data quality and processing efficiency enhancements, implementing infused tools and tracking developments are vital. For software scalability upgrade, it suggests optimizing SQL queries, implementing an effective database indexing system, and adopting a scalable distributed storage system.
 ObjectiveEnhance data engineering capabilities to drive software innovation
ObjectiveEnhance data engineering capabilities to drive software innovation KRImprove data quality by implementing automated data validation and monitoring processes
KRImprove data quality by implementing automated data validation and monitoring processes Implement chosen data validation tool
Implement chosen data validation tool- Research various automated data validation tools
- Regularly monitor and assess data quality
- KREnhance software scalability by optimizing data storage and retrieval mechanisms for large datasets
- Optimize SQL queries for faster data retrieval
- Adopt a scalable distributed storage system
- Implement a more efficient database indexing system
- KRIncrease data processing efficiency by optimizing data ingestion pipelines and reducing processing time
- Develop optimization strategies for lagging pipelines
- Implement solutions to reduce data processing time
- Analyze current data ingestion pipelines for efficiency gaps
Tability: the best OKR software for results-driven teams
OKRs should be tracked weekly to be effective, and Tability is the perfect tool for that.
Tability is the best OKR software that embraces modern principles to help teams set better goals, monitor execution, and get help to achieve their objectives faster.
With Tability you can:
- Get an OKR agent that can review existing OKRs, suggest improvements, and monitor execution
- Connect your OKRs and team goals to Jira, ClickUp, Linear, Asana, and more
- Automate reporting with integrations and built-in dashboard
You can import OKRs in seconds with the magic importer, and start executing your goals in no time.
Step 1. Sign up for a free Tability account
Go tohttps://tability.app/signup and create your account (it's free!)
Step 2. Create a plan
Follow the steps after your onboarding to create your first plan, you should get to a page that looks like the picture below.
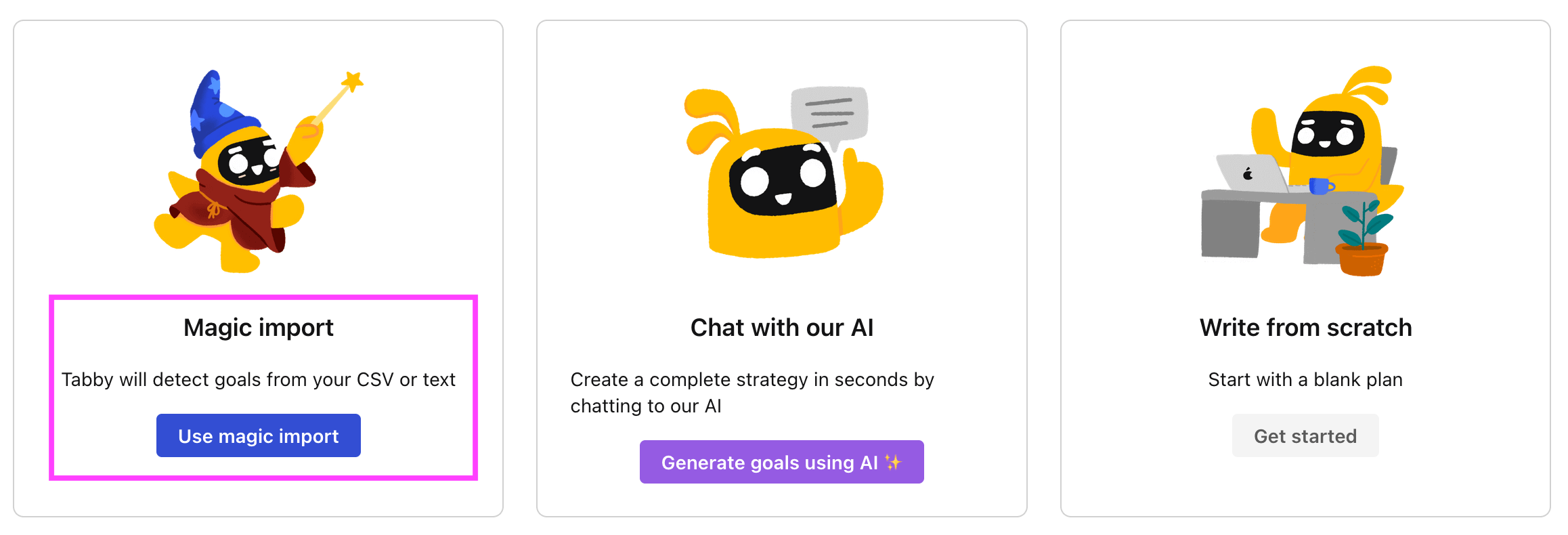
Step 3. Use the magic importer
Click on Use magic import to open up the Magic Import modal.
Now, go back to the OKR examples, and click on Copy on the example that you’d like to use.

Paste the content in the text import section. Don’t worry about the formatting, Tability’s AI will be able to parse it!

Now, just click on Import from text and let the magic happen.
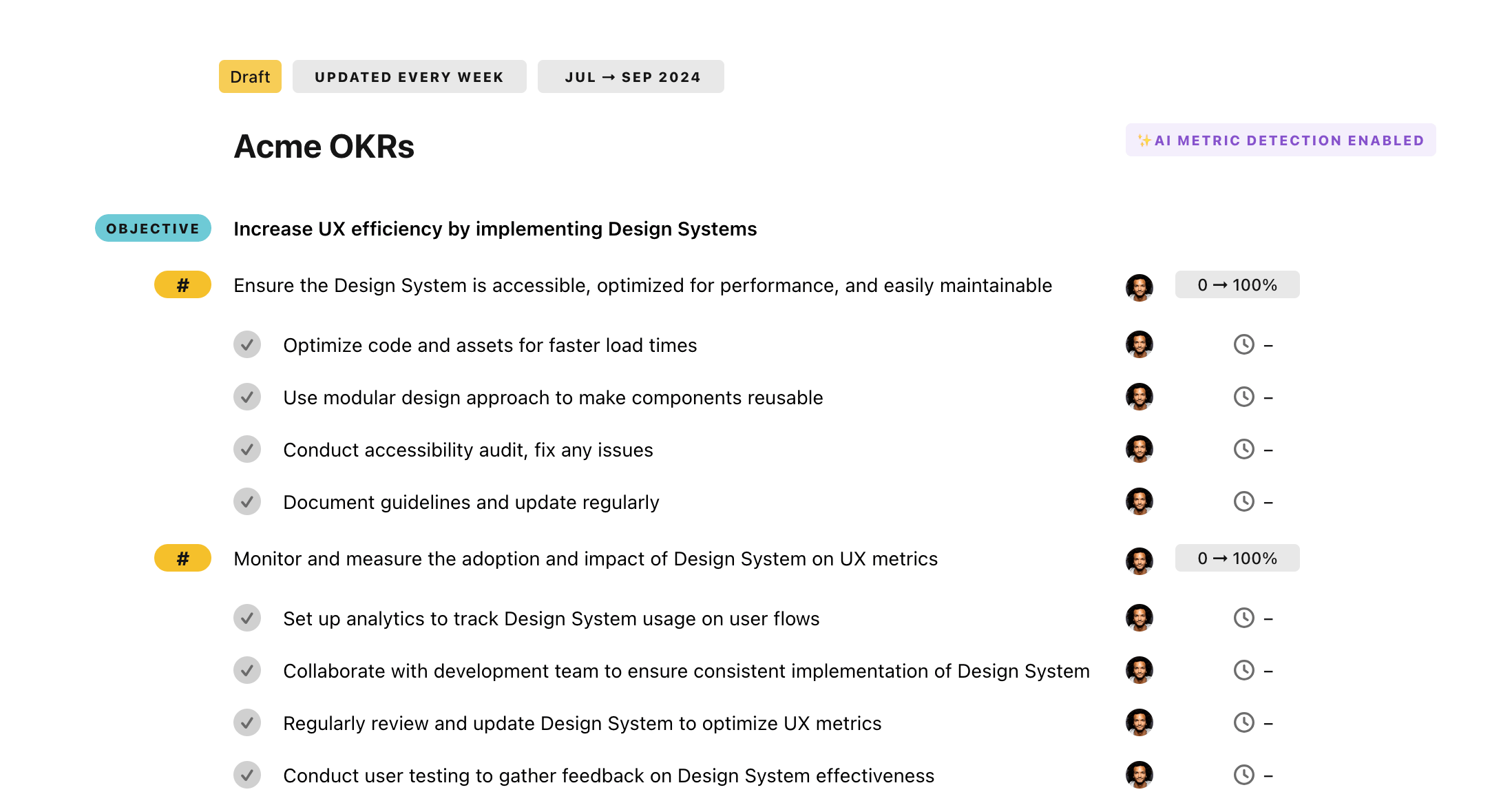
Once your example is in the plan editor, you will be able to:
- Edit the objectives, key results, and tasks
- Click on the target 0 → 100% to set better target
- Use the tips and the AI to refine your goals
Step 4. Publish your plan
Once you’re done editing, you can publish your plan to switch to the goal-tracking mode.
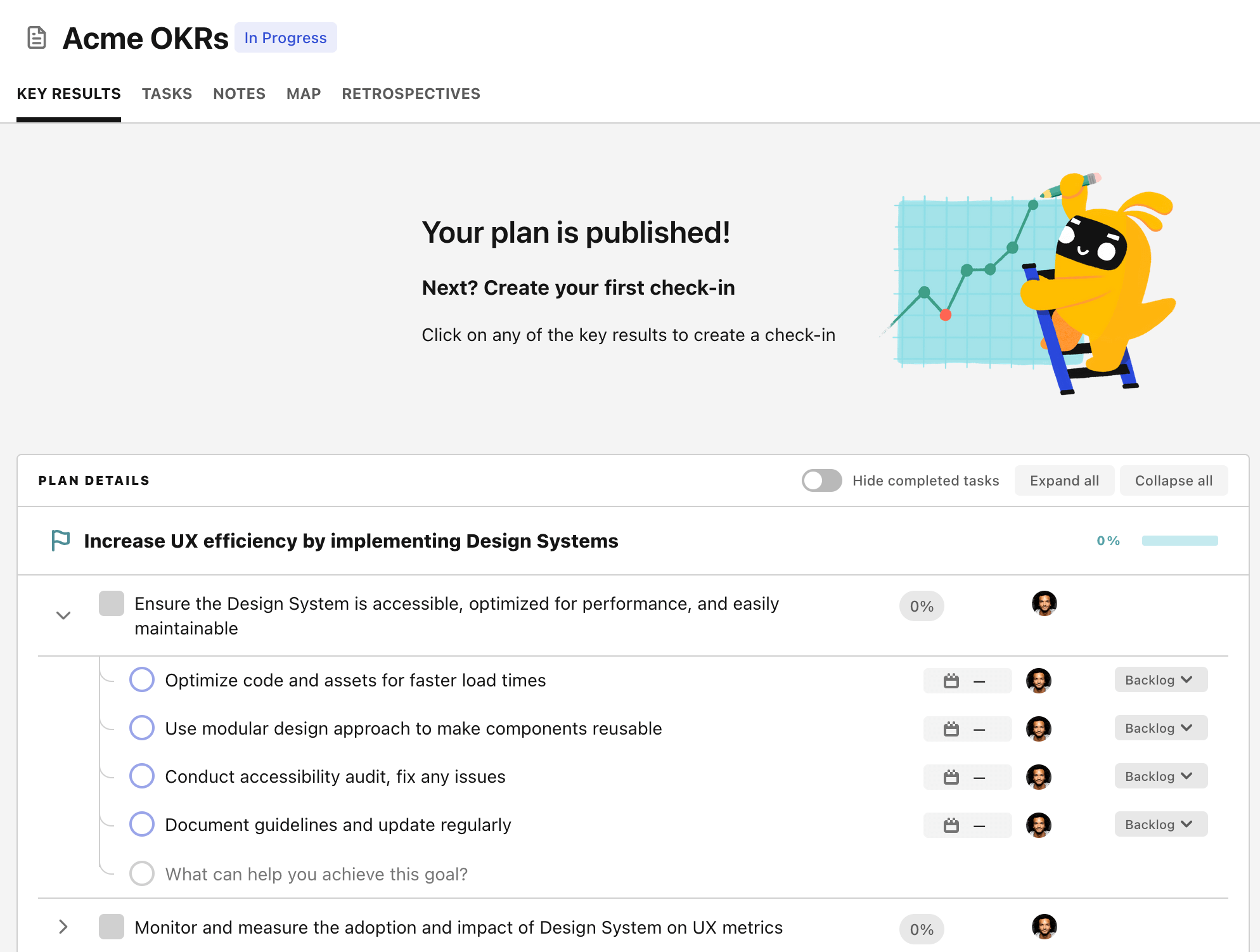
From there you will have access to all the features that will help you and your team save hours with OKR reporting.
- 10+ built-in dashboards to visualise progress on your goals
- Weekly reminders, data connectors, and smart notifications
- 9 views to map OKRs to strategic projects
- Strategy map to align teams at scale